
A couple of days ago I released the “stm-containers” library. In this post I’ll talk about the motivation behind the library, its features and performance.
Contents
Motivation
Why not a HashMap over TVars?
The type TVar (HashMap (TVar a)) seems to be an evident solution. The problem about it is that while this datastructure captures the updates to individual rows perfectly well, it is awful for capturing the updates to the table structure. I.e., deleting or inserting a row requires marking the outer TVar as changed, so multiple transactions cannot be modifying the table structure concurrently. Hence, it is not scalable.
How to solve this?
We need a data structure which will split the table into chunks in such a way that updating one chunk will not affect the other. This will allow multiple transactions to be effectively running on different chunks of the table concurrently without conflicts.
Hash Array Mapped Trie to the rescue
Essentially HAMT is an implementation of a hash table, which distributes the data across multilevel arrays (or lists). For details there is a great paper about this data structure.
This approach turned out to be very efficient for implementing persistent maps in particular, so it got adopted in languages like Clojure, Scala and, of course, Haskell with the “unordered-containers” library and earlier with the “hamtmap” library, which for some reason didn’t get much attention from the community.
As the current project proves HAMT also is a perfect candidate to implement the STM hash table based on. Essentially all we need to change about it is just place the nodes of the trie in TVars.
Features
The library comes with a set of standard functions for accessing and modifying the containers - nothing special here. However it also packs in one feature that stands out - the support for the “focus” API.
Focus
In short, focusing allows you to look up an item, decide whether to delete, update or do nothing with it, while producing some result based on this look up, and it performs it all as a single operation. Without focusing operations like this would require you to search thru the map two or more times.
Performance
The current source of the package comes with three benchmark suites. In all of them I measure only the performance of the map, since the set is implemented with the same internal data structure. In the benchmarks I use Text for keys and () for values, since values have no effect on performance of a map.
Following are the details and the results of running the benchmarks on my 6-core Intel Core i7-3930K clocked to 4.2 GHz.
Insertion Benchmark
This one compares the performance of a single-threaded insertion of a 100 000 rows by various libraries. It contains 5 subjects:
- STM Containers/focus-based. Insertion done using the
focusfunction. - STM Containers/specialized. The specialized
insertfunction. - Unordered Containers. The
HashMapof the “unordered-containers” library. - Containers. The
Mapof the “containers” library. - Hashtables. The basic mutable hash table of the “hashtables” library.
Here are the results:
 (HTML version)
(HTML version)
We can conclude the following:
- It performs on par with the the “containers” library.
- It is a bit slower than “unordered-containers”. Running the benchmark several times has shown that its performance is within 70-90%%.
- The insertion done with the
focusfunction, is only slightly slower than with the specializedinsertfunction. This means that running the composite strategies of the “focus” package will be quite efficient. However implementing the specialized versions ofdeleteandlookupin future will be beneficial.
Concurrent Insertion Benchmark
This one compares the performance of the focus-based and specialized insertion of “stm-containers” with TVar (HashMap (TVar a)) based on “unordered-containers” in various multithreading setups.
The subject titles are of the following form:
number-of-threads/number-of-operations-per-thread/title
The results:
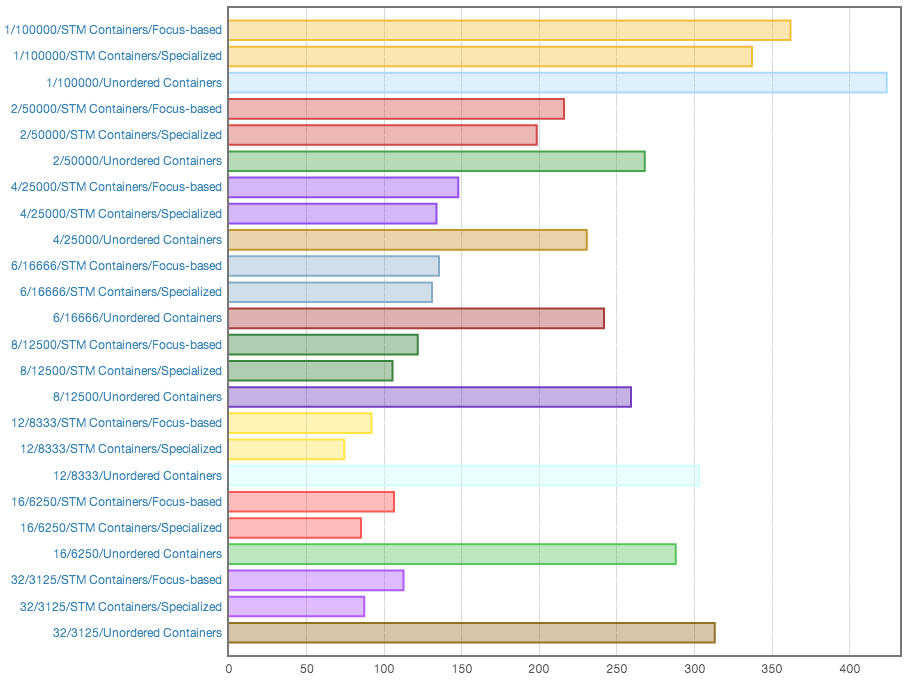 (HTML version)
(HTML version)
The conclusions:
- The “stm-containers” scale well up to 12 threads. This is quite expected for a 6-core hyperthreaded processor, which the benchmark has been run on.
TVar (HashMap (TVar a))basically stops scaling after 2-4 threads, which proves the suspicions from the beginning of this post.TVar (HashMap (TVar a))never reaches even a 2x factor of scaling.TVar (HashMap (TVar a))performs worse than “stm-containers” even on a single thread.
Concurrent Transactions Benchmark
This benchmark measures the general performance of the library. It generates 200 000 of random transactions, each consisting of multiple lookups, insertions and deletions and executes these same transactions in various multithreading setups.
You should be already familiar with the form of the subject titles:
number-of-threads/number-of-operations-per-thread
The results:
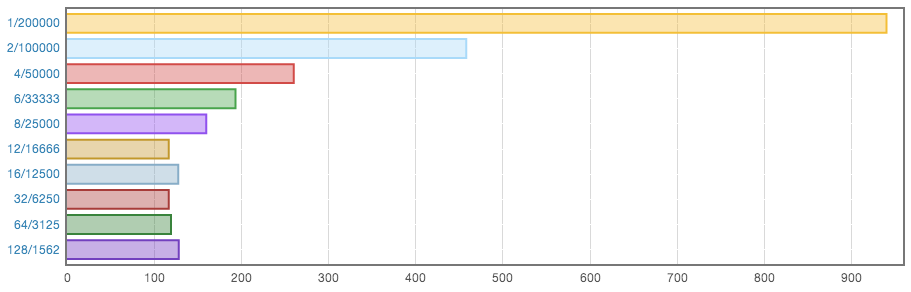 (HTML version)
(HTML version)
The conclusions:
- It scales amazingly well. The 2-thread setup executes 2 times faster. The 4-thread setup - almost 4 times faster. The 12-thread setup (the sane maximum of a 6-core hyperthreaded processor) is more than 8 times faster! IOW, it somehow squeezes out more performance than one would expect from a 6-core machine.
Ben, I need help!
From the benchmark results analyzed here, you can see that 6 cores is really not enough to test all the potential of the data structure. That’s why I’m asking those of you with huge amounts of processors to run the benchmarks and share the results.
To execute the benchmarks, check out the source tree, make sure that you have no processor-consuming apps running and execute the following command from the project’s root:
cabal bench insertion-bench --benchmark-options="-odist/insertion.html -g -s100" && cabal bench concurrent-insertion-bench --benchmark-options="-odist/concurrent-insertion.html -g -s100" && cabal bench concurrent-transactions-bench --benchmark-options="-odist/concurrent-transactions.html -g -s100"
When it finishes, you’ll find three HTML files in the “dist” directory. Please publish them.
Update
Christopher Biscardi has published results of running benchmarks on a 12-core Mac. Thanks, Christopher!